Answering questions about agent behavior requires measuring agents in realistic, messy environments. qlawbox is a five-layer architecture built to do just this, equipped with:
Each layer functions independently. When composed, they form a closed feedback loop whose behavior can be observed, internal dynamics traced, and interventions measured.
01 Knowledge + Learning: qortex
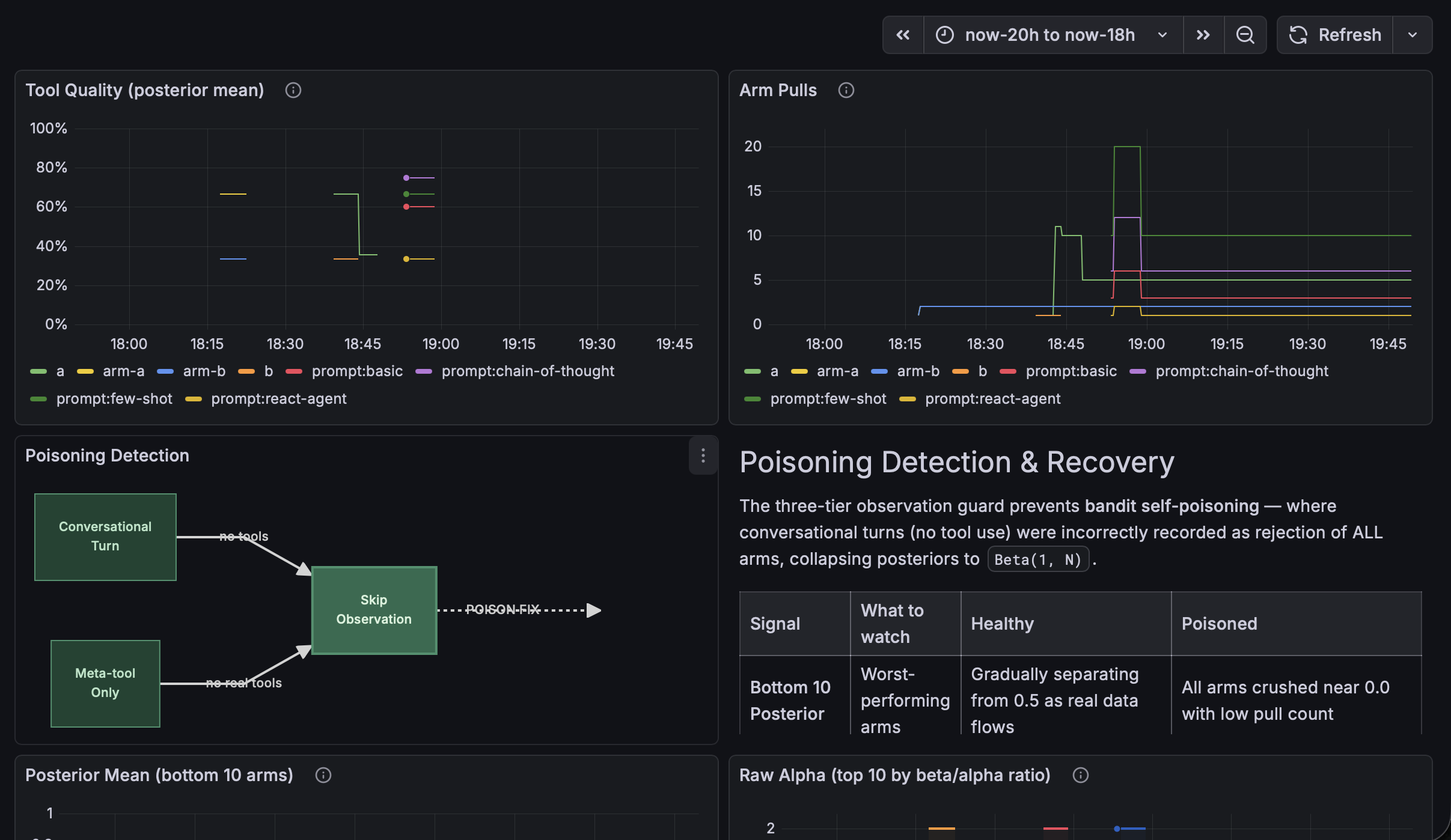
qortex frames context engineering as a learning problem. System prompt components, such as tools and other injected context, are modeled as arms of a contextual bandit. Per query, the agent samples Beta posteriors to decide what belongs in context; feedback updates those posteriors via Thompson Sampling.
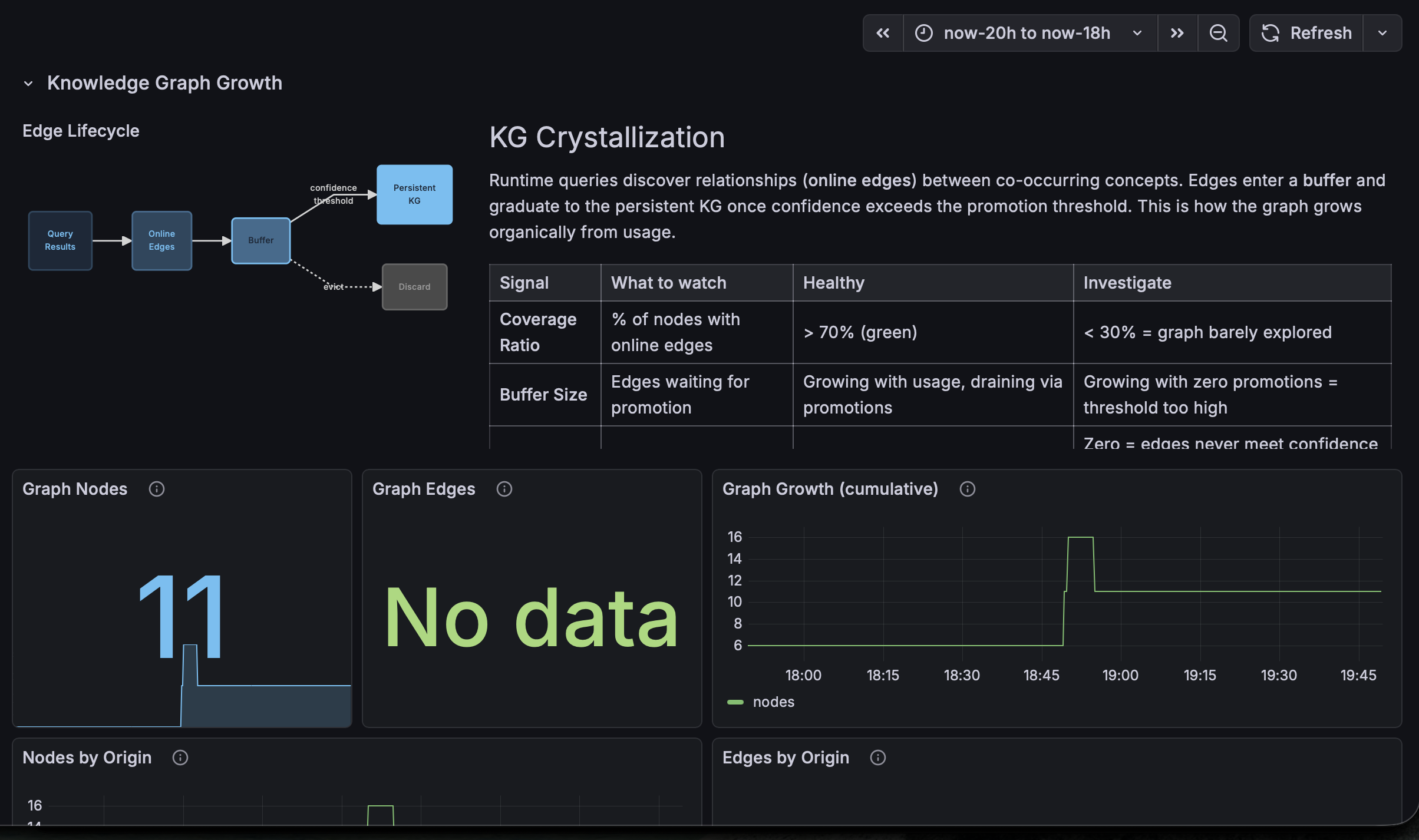
Beneath the bandit sits an experimental causal knowledge graph with typed edges, generated online via qortex-ingest. Feedback credit propagates backward through ancestor concepts, decaying by hop distance and edge strength.
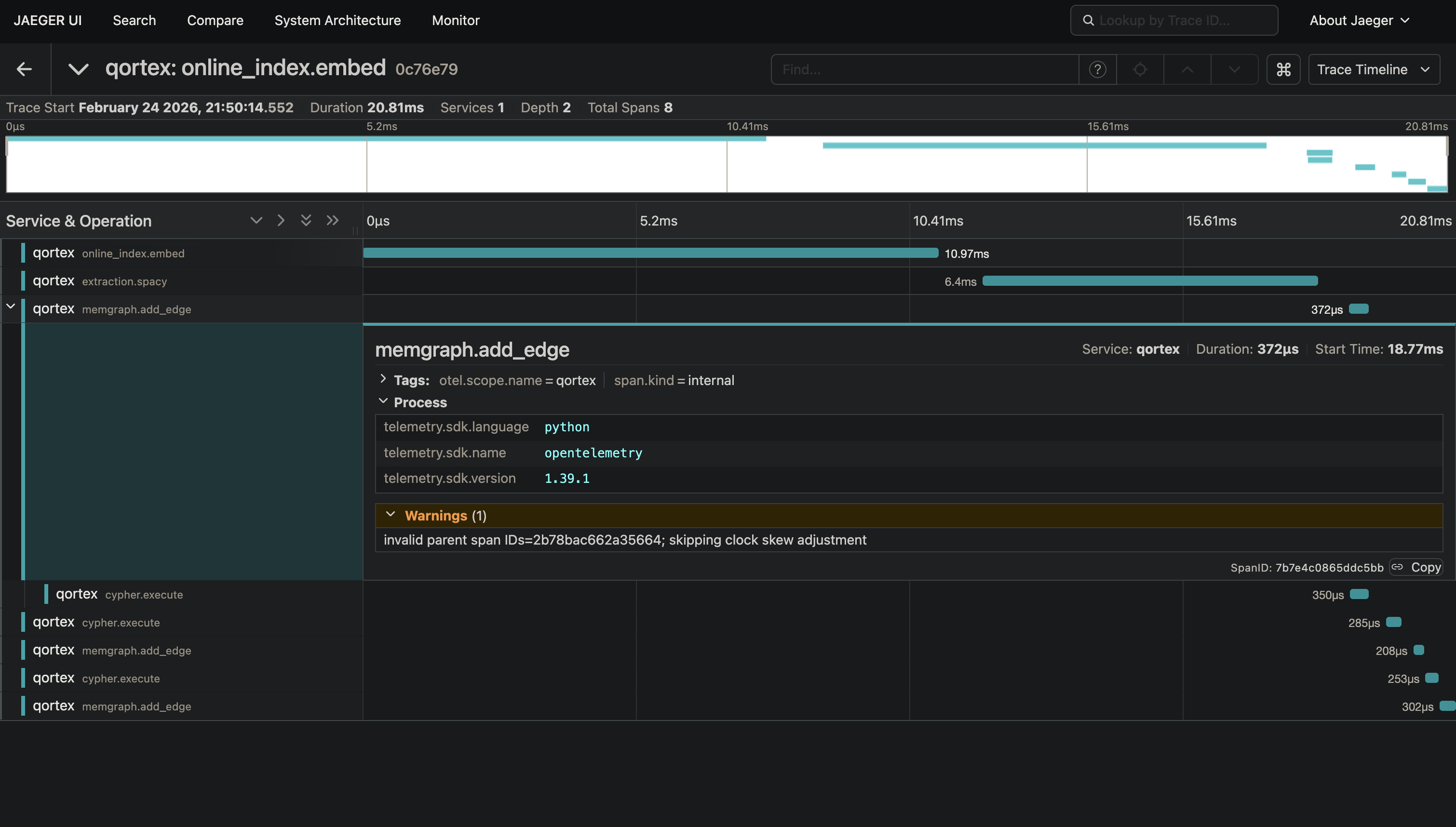
qortex-online handles real-time indexing into Memgraph. Preliminary results suggest positive impact on retrieval performance with minimal overhead.
As of recently, qortex is also a network service. qortex serve starts a Starlette ASGI server exposing 35+ REST endpoints with HMAC-SHA256 auth and replay protection. Postgres backends (pgvector for embeddings, dedicated stores for Thompson Sampling arm states and interoception factors) replace the local SQLite defaults. Any language that speaks HTTP can now consume the full knowledge and learning stack.
7 framework adapters, each built against its framework's own test suite:
CrewAI,
Agno,
AutoGen,
LangChain,
LangChain.js,
Mastra,
Vindler (fork: OpenClaw).
Every selection, observation, and posterior update in the learning layer emits a structured event. qortex-observe routes those events to three export paths:
- JSONL file sinks for offline replay
- OpenTelemetry spans for distributed tracing via Jaeger
- 48 Prometheus counters/gauges/histograms for real-time Grafana dashboards
MCP tracing middleware wraps each tool call with distributed trace context, so a single query can be traced from inbound message through graph traversal, vector retrieval, posterior sampling, and credit propagation.
A note on emphasis: this layer leans on OpenClaw because it's a convenient, realistic agent to exercise and measure qortex. It's a test surface, not the thesis. The point of the stack is the knowledge-and-learning layer and its instrumentation; any agent runtime would do.
vindler is a hardened fork of OpenClaw, rewired as the qlawbox agent runtime.
The fork replaces OpenClaw's memory layer with qortex and instruments every tool call and retrieval path through qortex-observe.
bilrost (PyPI) locks the runtime inside a Lima VM with OverlayFS for filesystem isolation and UFW NACLs for network policy. Network access is network-as-needed: tools declare their requirements and bilrost opens only those ports for the duration of the call.
Vindler also grew a LinWheel extension: 17 MCP tools for LinkedIn content operations, covering content processing, drafting, post management, voice profiles, and visual generation. All tools are opt-in (declared optional: true) and only activate when explicitly allowlisted. An approval gate (post_approve) is required before anything reaches post_schedule.
The codenames are Norse. In the Eddas, Bifrost (also spelled Bilrost) is the flaming rainbow bridge situated above the world-tree Yggdrasil, binding Miðgarð to Ásgarð. The only path in, it burns anything unwelcome that dares try to cross. Vindler is Heimdallr, the guardian of heaven's gates.
Typed signal bus for ambient agent behavior.
Rather than waiting for prompts, it lets agents subscribe to event streams and act when conditions are met. cadence classifies, prioritizes, and dispatches signals to the appropriate handler.
Internal state signals from the interoception layer route alongside external events through the same bus, so the agent's response to its own dynamics is handled by the same dispatch infrastructure as its response to the outside world.
Intended to interop with interoception to trigger spontaneous "speech" in response to shifts in internal state and predictions thereof. Very early stage and highly speculative, but a fundamental part of the long-term research horizon.
Docs ↗
An analog of biological homeostasis.
The agent monitors its own conservation quantities (posterior stability, convergence rate, reward variance) and flags violations as affect signals: confusion, surprise, dissonance, novelty. Each signal maps to an observable property of the learning dynamics.
This is the most speculative layer. For now, it serves as an architectural placeholder for experimenting with internal signals, pointing cadence's ambient awareness inward, so agents can generate speech based on their perception of internal state and predictions about where that state is heading.
Like cadence, this is very early stage and highly speculative, but it represents a fundamental piece of the long-term research direction: agents that respond not only to the world, but to themselves.
Docs ↗