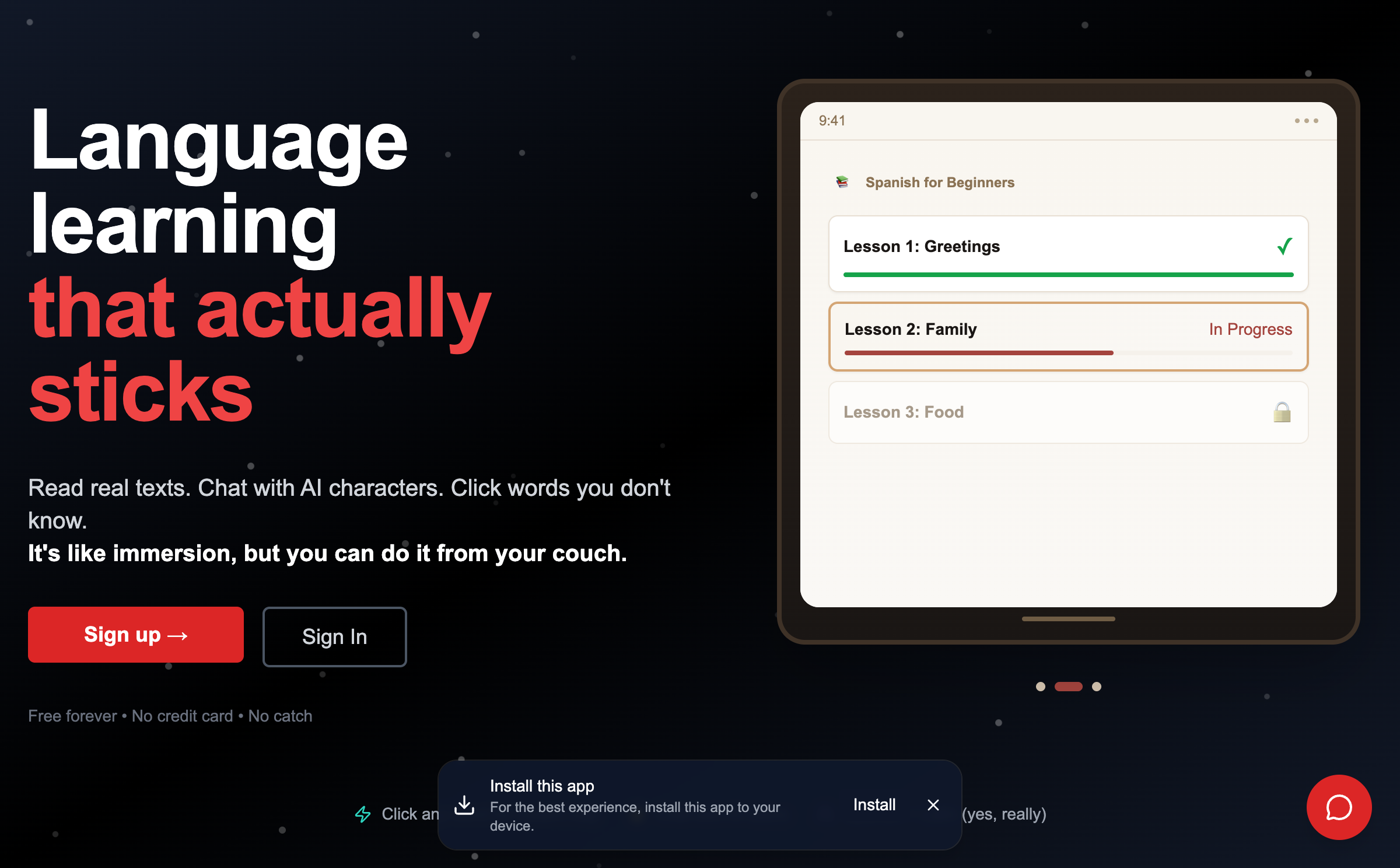
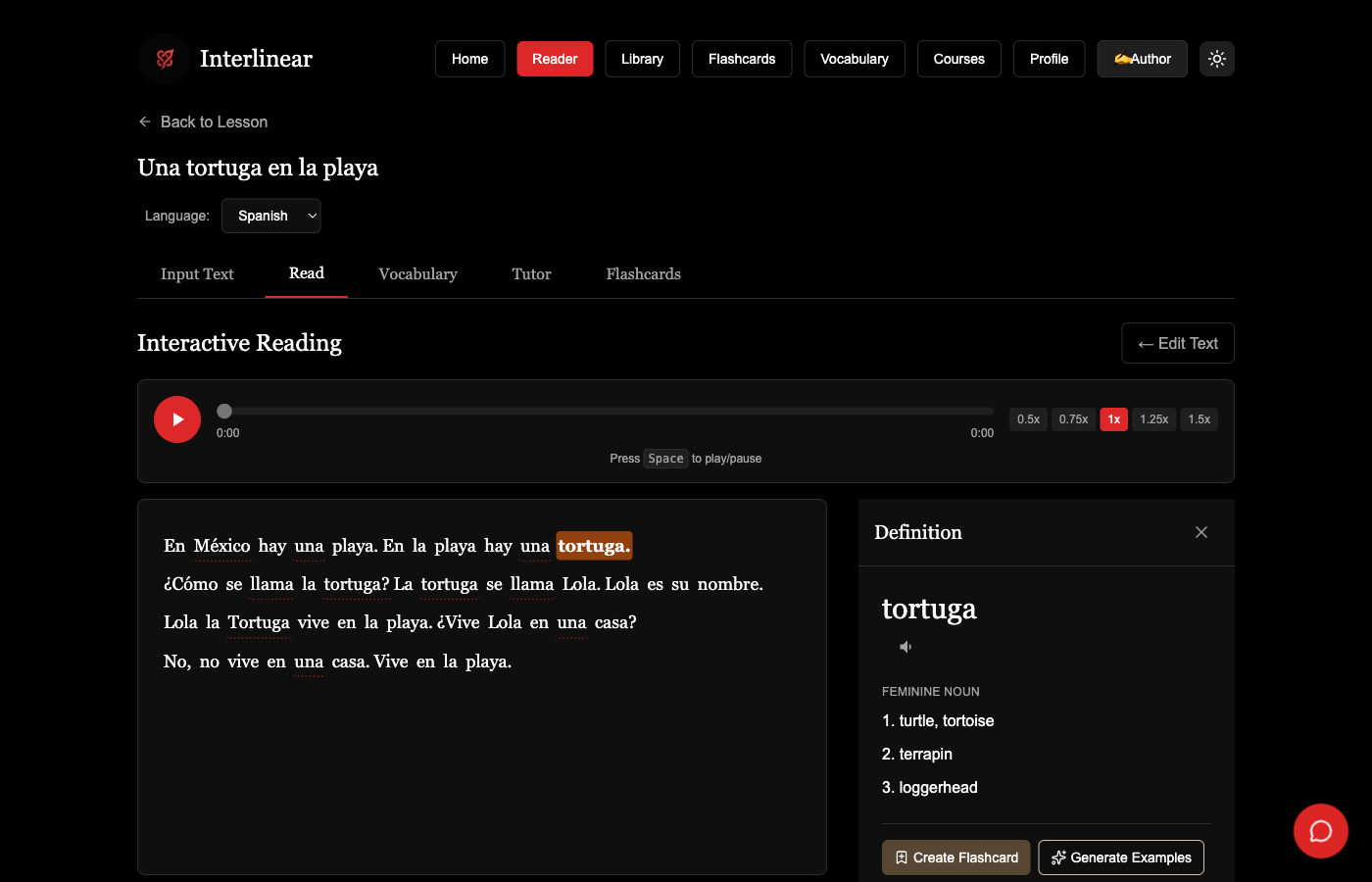
The tutor runs as a set of typed LangChain graphs (lib/ai/graphs): a turn graph for live conversation, an onboarding-assessment graph that reads a short conversation to place you on the CEFR scale, and a content-generation graph that turns a reading into exercises, dialogs, grammar notes, and vocabulary at your level. Model calls go through a provider-agnostic layer, so the same graph runs on any LLM backend and switches providers with a config change.
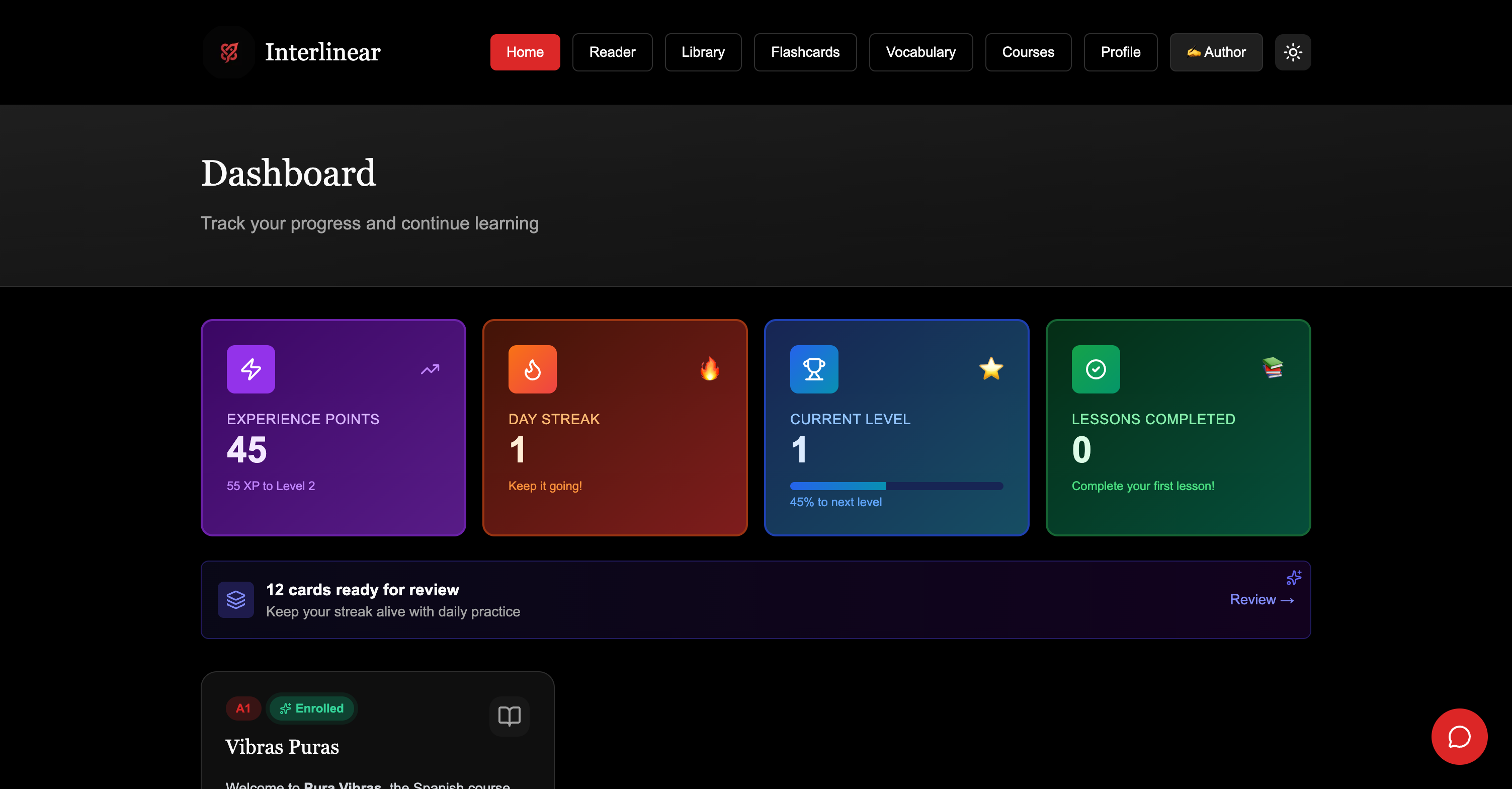
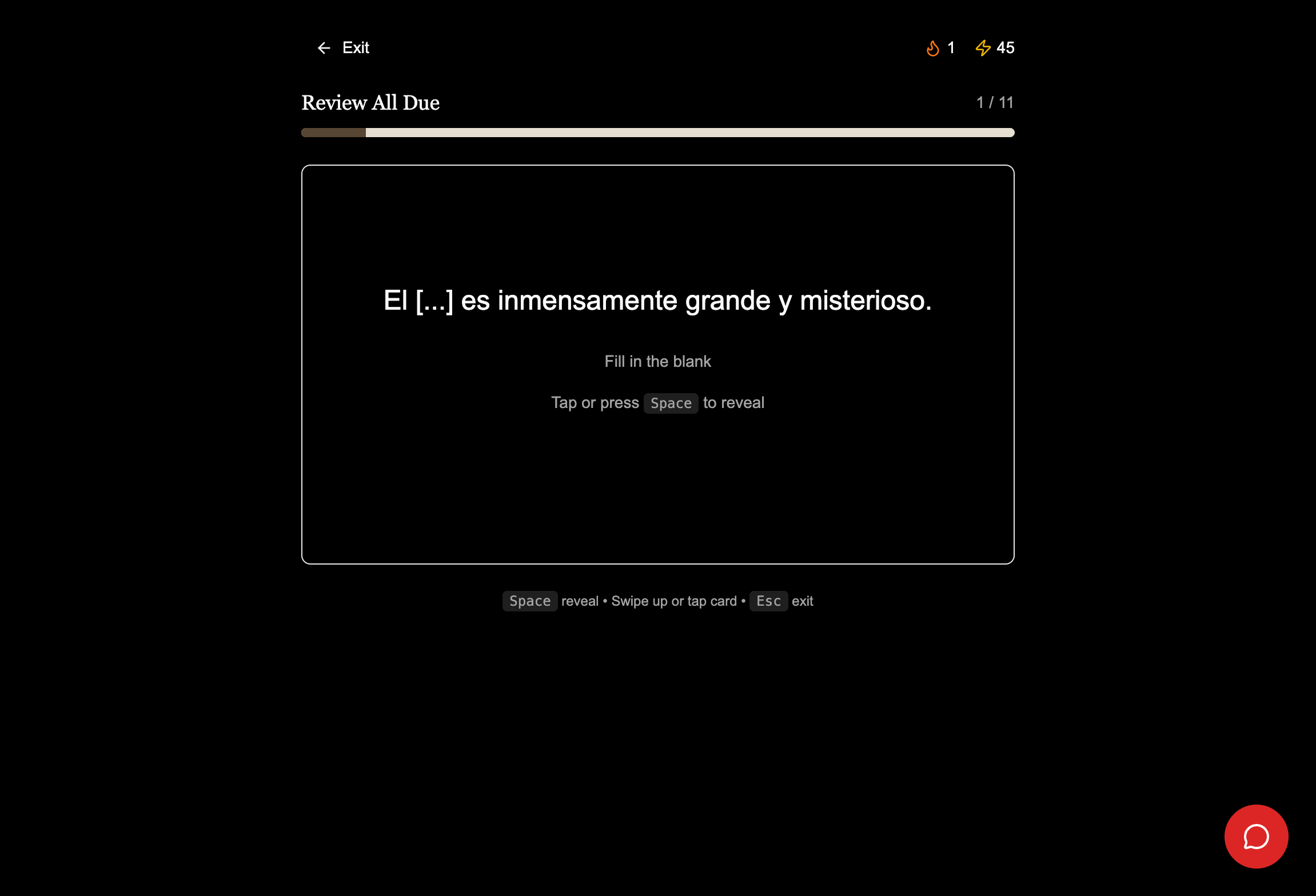
Error analysis is the core. Tutor feedback is classified into three categories (grammar, vocabulary, syntax), and each triggers a different response, the same way a production LLM eval separates a retrieval failure from a reasoning error from a formatting slip. CEFR is the coordinate the system places you at; a difficulty mapping then pitches generated content just above it rather than locking you to the rung.
Classical languages get real inflection analysis instead of string matching. A dedicated FastAPI microservice wraps CLTK and Stanza for Latin morphology, resolving each form's case, tense, and person as you read it; Icelandic vocabulary and lemmas come from the ensk.is API. ElevenLabs handles TTS, cached aggressively to cut repeat cost.
Today the system places you with CEFR and tunes difficulty per interaction. The deeper version (per-concept mastery: tracking which grammar you have internalized versus which you keep missing, and feeding that into what content comes next) is designed against qortex, my learning layer, and not yet wired in production. The branch that joined them never merged.